| |

Compelling Stand-Alone Evidence that the Torah
is Encoded
How long would a code need to be for it to serve as sufficient evidence, all on its own, that the Torah is encoded? We show in this article that any code 224 letters long, or longer, would qualify as sufficient evidence. That is assuming the code has a skip of 10 or less and a probability threshold of one in one billion and that, put another way, the chances of finding that long a code (with a very short skip) in a non-encoded text are less than one in one billion.
In this issue, Moshe Shak presents a 296-letter-long ELS regarding Shimon Peres that he found in the Torah. Not only is this code 72 letters longer than it needs to be to cross the threshold, it also is comprised of 30 sentences. These sentences outline, in chronological order, the different phases of Peres' political career. In addition to the extreme length of this code, it also has a very short skip of eight. And this unbelievably long ELS is part of an extensive matrix of other ELSs about Peres that includes numerous other long ELSs.
Encountering this mammoth code and its accompanying matrix is much like going to a museum and seeing the entire skeleton of a 40-foot-high tyrannosaurus rex. If you ever had doubts that dinosaurs once existed, those doubts would be dispelled.
It doesn't take a probability expert to realize that this marathon ELS is extremely unlikely to be a coincidence. But, just how unlikely is it?
We calculated the odds by making the highly conservative assumption that Shak had been able to exhaustively search all possible maximal ELSs (with a skip of 10 or less) that could be extracted from the Torah. Under these assumptions, we determined that the odds that the longest ELS would be 296 letters long, or longer, are less than
1 in 2,775,000,000,000,000.
How unlikely is that? Suppose you were standing on a beach that was three miles long and 100 feet wide and the sand was exactly one foot deep for the entire beach. The sand is fine enough that 100 grains laid end to end would measure one inch. You take one grain of sand and dye it bright red and then go to a randomly selected location on the beach and bury it at a random depth (i.e., somewhere between the surface and one foot down). Then you blindfold someone and have them go to a different random location on the beach and have them go down to a random depth within the sand and pick up one grain of sand with a pair of tweezers. The odds that the selected grain of sand would be bright red would be the same as Shak finding an ELS 296 letters long or longer if he had exhaustively searched for every possible ELS (with a skip of 10 or less) within a non-encoded Hebrew text the same length as the Torah.
In reality, there is no way that Shak could have examined all of the initial ELSs in the Torah for possible extensions. There are over 50,000,000 such ELSs. We asked him to provide a realistic estimate of how many initial terms he has searched for extensions over his lifetime. He's been searching an average of 70 days per year for the past six years, and on average he has checked about 10 terms per day. That works out to 4,200 terms. We assumed 5,000 terms just to be conservative.
Next, we figured out the odds using the more realistic assumption that Shak has examined 5,000 terms for possible extensions over the last six years. The odds that Shak would have found a code as long, or longer, than 296 letters is less than
1 in 269,000,000,000,000,000,000,000.
How unlikely is that? Suppose that the entire continental United States were covered two feet deep with the same type of beach sand as in the first example. You take one grain of sand and dye it bright red and then go to a randomly selected location within the U.S. and bury it at a random depth (i.e., somewhere between the surface and two feet down). Then, you blindfold someone and fly them to a random location within the U.S. and have them go down to a random depth within the sand and pick up one grain of sand with a pair of tweezers. The odds that the selected grain of sand would be bright red would be the same as Shak finding an ELS 296 letters long, or longer, if he had been searching a non-encoded Hebrew text.
So, bottom line, discovering a 296-letter-long ELS with a skip less than 10 from a non-encoded text is so improbable that it is appropriate to firmly conclude that the Torah is encoded.
In figuring these odds, we haven't factored in the added improbability of numerous long codes that are also part of the Peres matrix. Nor did we factor in the chances that the sentences in the code would describe events in Peres' career in chronological order. Doing so would make the odds noticeably more remote.
The technical addendum that follows provides many of the details relating to our calculation of the odds of chance occurrence of the 296-letter-long code.
Using the conservative set of assumptions, we can also determine how long a discovered code (with a skip of 10 or less) would need to be to reject the null hypothesis that the Torah is not encoded. If the threshold were one in one thousand, the discovered code would need to be 147 letters long, or longer. If the threshold were one in one million, the code would need to be 182 letters long. If one in one billion, 224-plus letters would be needed. And if one in one trillion, 259-plus letters would be required.
Technical Addendum
The mathematical tools for answering the question of whether a 296-letter ELS is impossibly long are readily available. The problem can be neatly broken down into a few parts, once we consider the steps taken in discovering the very long ELSs unearthed in the past five years. Those steps are:
- Find a reasonably short search term as an ELS within the search text. Suppose this term had a skip of eight, the same as Shak's initial search term will not be elected.
- Display the search term within a single column in a matrix with the same number of columns as the skip of the initial ELS.
- Examine the string of Hebrew letters above and below the search term to see if the search term is part of a longer ELS in good Hebrew. For example, Shak found therefore my name right before will not be elected as one extension and the one that opposes that misleads right after the original term as a second extension.
- If the extended ELS comes close to either the top or bottom of the matrix, expand the matrix and continue examining the column of letters to see if there is an even longer ELS of which the initial search term is a part.
Not uncommonly, several search terms are examined for possible extensions. The thorough researcher will keep track of all search terms reviewed for extensions. It would be best if the researcher would also report this information together with his or her findings. Unfortunately, many code researchers are not in the habit of doing this, leaving the reviewer of their findings wondering just how long they had to work to come up with their discoveries. To calculate the probability of random occurrence, it is necessary to know how many search terms were examined for extensions.
In step three above, one of two results will occur in each instance that there is an opportunity to find an extension of the initial ELS. If no extension is found, this will be denoted by [Gibberish] and if one is found, by [Extension].
So the Hebrew expert starts with:
[preceding letters] [Initial ELS] [succeeding letters].
Four possible things can happen:
- [Gibberish] [Initial ELS] [Gibberish]
- [Gibberish] [Initial ELS] [Extension]
- [Extension] [Initial ELS] [Gibberish]
- [Extension] [Initial ELS] [Extension].
Once a Gibberish occurs, the search process is over on that side of the ELS. But if an extension is found, then there is an opportunity to find yet another extension. So if [Gibberish] [Initial ELS] [Gibberish] happens, the search is over. But if [Gibberish] [Initial ELS] [Extension] happens, two things could result from the additional search:
[Gibberish] [Initial ELS] [Extension] [Gibberish]
[Gibberish] [Initial ELS] [Extension] [Extension].
If the first sequence of events occurs, the process is over. But if the second sequence occurs, two things could result from the additional search:
[Gibberish] [Initial ELS] [Extension] [Extension] [Gibberish]
[Gibberish] [Initial ELS] [Extension] [Extension] [Extension].
And so forth. By calculating the probability that each of these events could occur by chance, and organizing the results in a certain way, it is possible to simplify all this down to a straightforward formula. This is done in Appendix B of the paper Non-Random Equidistant Letter Sequence Extensions in Ezekiel. This derivation also appears in Appendix Seven of Bible Code Bombshell.
The formula for the expected number of ELSs with k extensions to emerge from an examination of an initial group of n ELSs found in a text is:

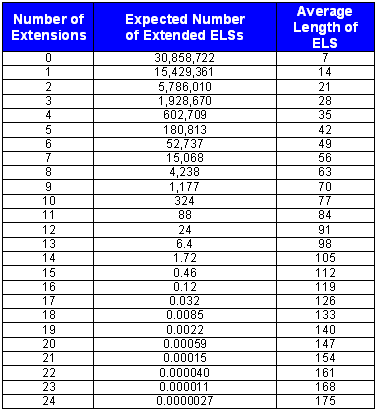
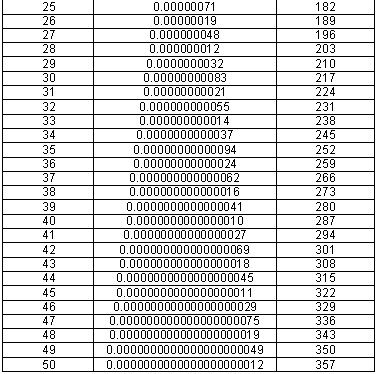
What the above table is saying is that of the 54,859,950 possible ELSs examined for possible extensions, for 30.8 million of them, no extension was found in good Hebrew. For 15.4 million, one extension was found; for 5.7 million, two extensions were found; and so forth. For only one initial search term did the final code consist of 15 or more extensions.
In each case, the key assumptions that went into the above calculations were made on the conservative side, so that it would be clear that the real odds would be less than what the calculations derived. The key assumptions are:
1. Total Number of ELSs Examined for Possible Extension: 54,859,950.
We assumed that every possible ELS consisting of two to 10 letters with skips ranging from one to 10 consists of a valid Hebrew word or words. We then applied the following formula from Appendix One of Bible Code Bombshell:
Formula 1C. The total number of possible ELSs with L skips (including both forward and backward ELSs) that can fit within a text of T letters, when the skip can be any number between one and N is:
N* [2T - L - N*L].
This assumption is highly conservative because a large percentage (e.g., 70% to 80%) of the ELSs will consist, at least in part, of gibberish. Also, there will be quite a bit of duplication of words within this set. For example, suppose that Peres loses is one of the 10-letter-long ELSs (assuming, for illustrative purposes, that the ELS is in English when it actually is in Hebrew). Then both Peres and loses will also be counted separately as two 5-letter-long ELSs.
2. Discovery Rate of Extensions: 25%.
In the scientific paper, Non-Random ELS Extensions in the Book of Ezekiel, the extension discovery rate from the non-encoded text of a Hebrew translation of Tolstoi's novel, War and Peace, was 19.4% from one of our Hebrew experts (Dr. Nathan Jacobi) and 18.7% from our second Hebrew expert (Moshe Aharon Shak). So we selected 25% as a conservative estimate of the discovery rate.
3. Total Number of Extensions in the 296-Letter-Long ELS: 41.
In the chart on the long Peres code, 30 different sentences are shown. However, for 11 of these sentences, their content was complex enough that there were two extensions within those sentences.
In deriving the probability of finding a code that was 296 letters long, or longer, we totaled the expected number of occurrences for the situations of 41 or more extensions. For extremely small probabilities, the probability of occurrence is virtually the same as the expected number of occurrences. [This is not true when the expected number of occurrences is greater than 0.1.]
The Effects of Making the Probability Estimate Fully Realistic
Rather than staying on the conservative side in selecting assumptions one and two above, how would the computed odds change if we used fully realistic assumptions instead?
As it is, the computed odds were less than:
1 in 2,776,262,374,820,970.
Using fully realistic assumptions, the odds would change to:
1 in 725,868,629,782,817,000,000.
In other words, it would have been 261,000 times more improbable.
In doing this we assumed 15,000,000 initial search terms for the first assumption and a discovery rate of 19% for the second assumption.
|
Enjoy finding your own Bible codes.
Bible code search software is available in our online store.
Subscribe Free! Sign Up Today!
Become a member of the non-profit Isaac Newton Bible Code Research Society.
Not only will you be part of the world's leading organization researching and publicizing Bible and Torah codes, but you will receive Bible Code Digest absolutely free, including . . .
- Latest Bible Code News
- Easy-to-Understand Bible Code Feature Articles
- Exciting Inside Information from Leading Code Researchers
- Details of Great New Discoveries
- Summaries of the Latest Battles Between Code Proponents and Skeptics
Stay current on Bible code news. Be first to hear about all of the latest Bible code discoveries.
Sign up to receive Bible Code Digest today.
|
|


 
Bombshell examines two massive, recently discovered clusters of codes in the Hebrew Old Testament. To read more about Bombshell, click here, or click below to order from Amazon today!

|

